 Chapter 22 One-Way Analysis of Variance: Comparing Several Means
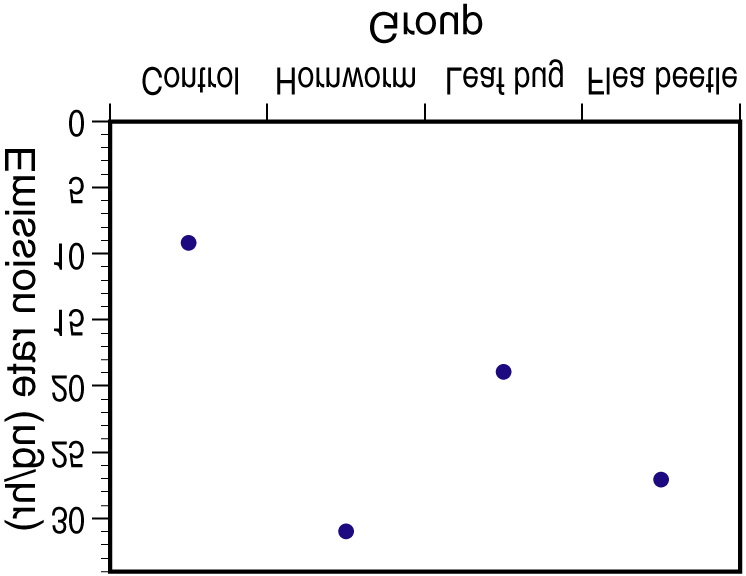
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5,
Chapter 22 One-Way Analysis of Variance: Comparing Several Means
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5, Microsoft word - 1-regulamento cdo 2013
(Regulamento do Campeonato Divinopolitano de Orientação 2013) CLUBE DE ORIENTAÇÃO DE DIVINÓPOLIS - CODIV Rua Manoel Bandeira 100, Bairro Santa Luzia – CEP: 35501-199 Divinópolis - MG. Fundação: 21 de janeiro de 2010 CNPJ: 11.795.075/0001-22 Fones: (037) 88233628– (37) 3212 4506 (Enzio) www.codiv.org.br REGULAMENTO DO III - CAMPEONATO DIVINOPOLITANO DE ORIENTAÇÃO/2013